【技术解析】PaperBanana多智能体流水线:如何实现顶会级Figure自动生成
2024年的某个深夜,我盯着屏幕上手绘的方法框图发呆。箭头连错、字体不齐、配色混乱——这些问题几乎折磨过每一个科研工作者。我们投入数月做实验,却在最后「画图」这一步消耗大量时间,逻辑清晰的研究因为一张劣质Figure而大打折扣。
核心痛点:AI绘图工具为何难以胜任学术插图
传统的图像生成模型(DALL·E、VLM等)存在根本性缺陷:模块与文字对不上、字体乱码、箭头逻辑错误。这些模型追求「好看」,却忽视了学术插图最核心的要求——「正确」。
学术插图是论文叙事的组成部分,必须忠实反映算法逻辑、数据关系和科研规范。一张合格的Figure需要:模块间逻辑关系准确、数据表达符合科研标准、图直接服务于论文论证。这不是装饰需求,而是科研表达的基本规范。
技术方案:PaperBanana的多智能体协作架构
北大与GoogleCloudAIResearch团队推出的PaperBanana,采用了多智能体流水线架构,彻底改变了学术插图生成方式。
第一阶段:结构化规划。系统检索参考范例,对原始论文进行结构化描述,在审美规范约束下生成初稿。第二阶段:视觉转化。视觉代理将文本描述转化为图像或代码绘图,此处采用AI写代码(基于Gemini-3-Pro)再生成统计图的技术路线,避免了直接生成导致的数据错误。
第三阶段:迭代优化。评论代理对照原始论文内容持续纠错打磨,经多轮迭代后输出满足语义正确性与顶会审美标准的论文级插图。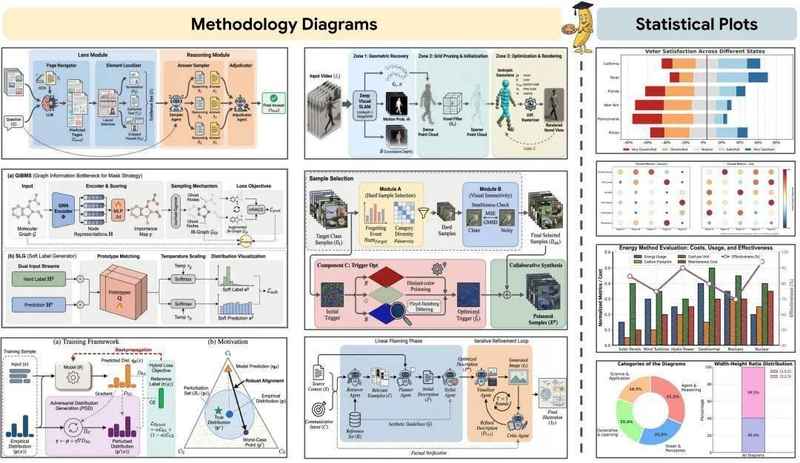
覆盖场景与核心能力
PaperBanana覆盖四类学术插图:方法流程图、模型结构示意图、概念性框架图、高精度统计图。系统支持从零生成和润色增强两种模式。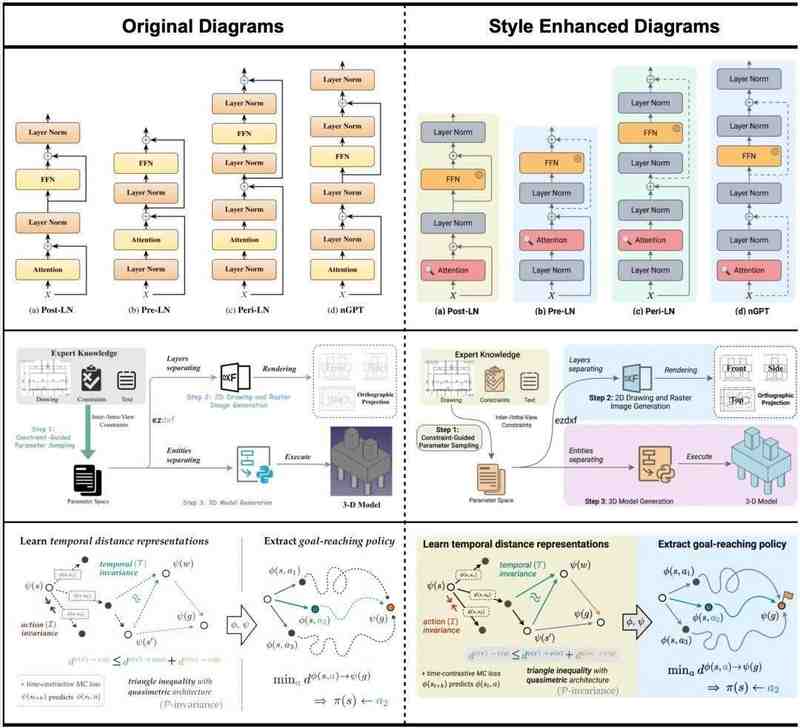
润色模式的价值在于:输入草图或初版框图,自动美化重排布局、统一风格。视觉增强后的图通过颜色区分功能模块、用虚线和分区框强化层次结构、箭头走向更加明确,整体观感接近顶会论文标准范式。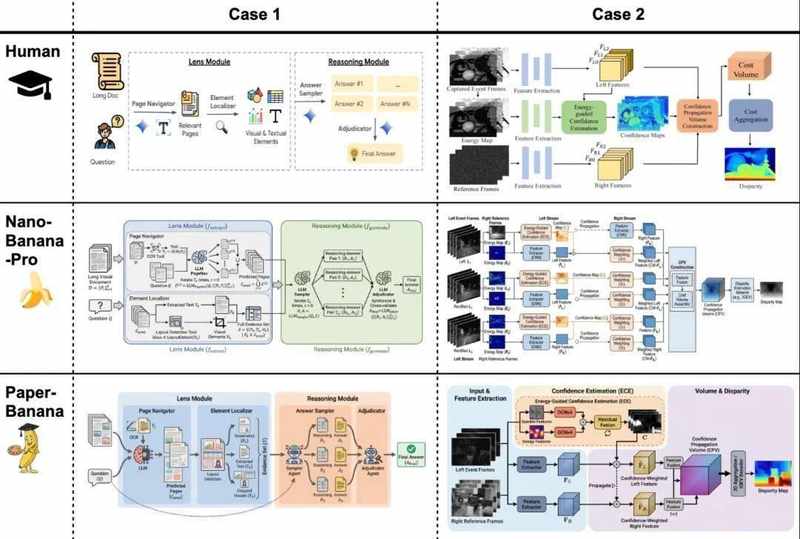
实践验证与结论
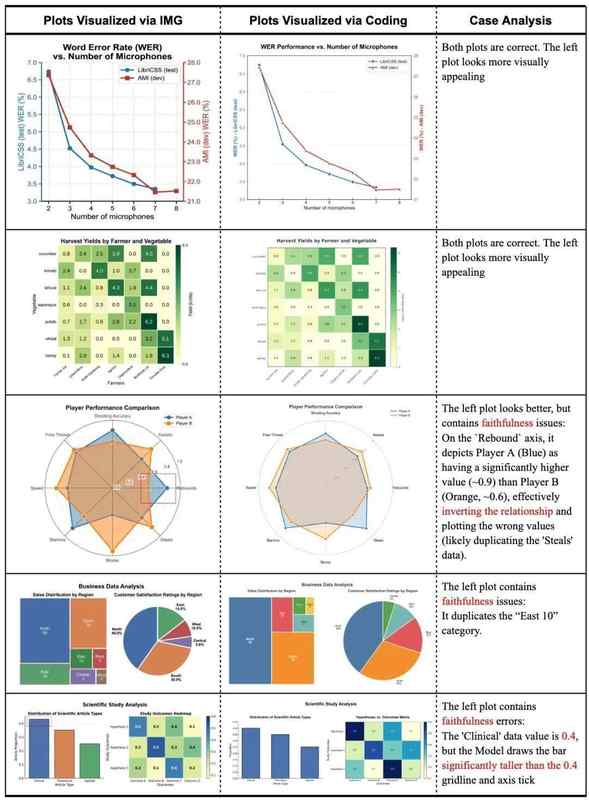
对比实验表明:AI直接绘制虽然精美,但经常在数字上出错;代码驱动方式(AI写绘图代码再生成)是目前最可靠的方案,兼顾精度与美观。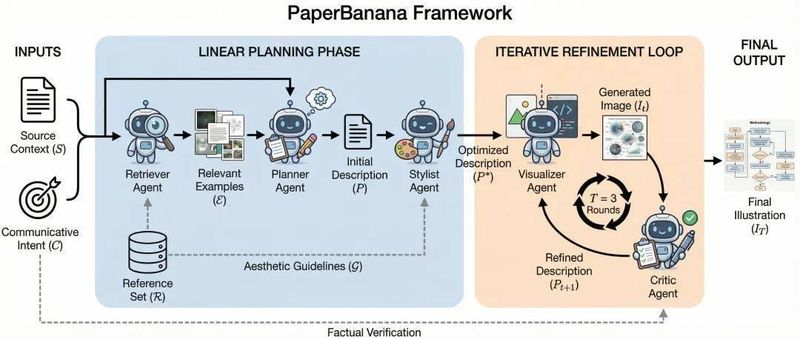
PaperBanana的意义超越了工具本身,它代表了一种「科研表达方式自动规范化」的新范式。对于科研工作者而言,这意味着可以把更多时间留给真正重要的研究本身。